|
Dota - Tianai DongHi! I am a fourth-year (and final-year) PhD student, affiliated with Multimodal Language Department at the Max Planck Institute for Psycholinguistics, and Predictive Brain Lab at the Donders Institute (Centre for Cognitive Neuroimaging). I am funded by an IMPRS fellowship in Language Science. My work focuses on understanding language and its interaction with the physical and social world. I take an interdisciplinary approach, combining computational methods —such as machine learning and bayesian modeling— with insights from neuroscience, linguistics, and psychology to better understand the human mind and advance artificial intelligence.
Fun Fact: Dota is actually my real, preferred name. It comes from my Mandarin initials, no connection to the game;). My family started calling me that, my friends picked it up, and it’s stuck ever since (in the best way).
If you’d like to discuss academic topics, feel free to get in touch :).
|

|
|
|
|
2026 Jul
🎉 Using Perspectival Words Is Harder Than Vocabulary Words for Humans —and Even More So for Multimodal Language Models has been accepted as a main paper at ACL 2026 — looking forward to presenting in San Diego! I'll also be visiting and giving talks at the Developing Intelligence Lab and KOALAB at UT Austin, July 13–17. Feel free to reach out if you'd like to chat :) 2026 May
🧠💭🤖 The very popular Workshop on Representational Alignment is back at ICLR 2026 in Rio! |
|
|
|
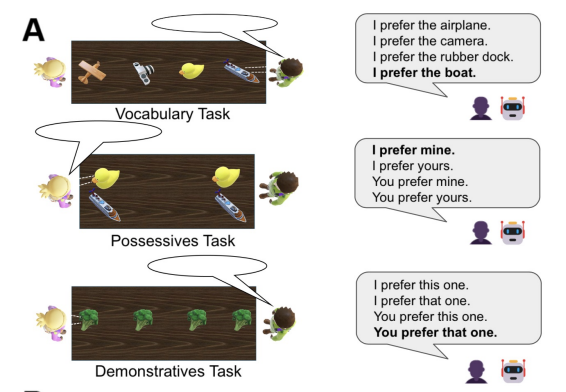
Dota Tianai Dong*, Yifan Luo*, Po-Ya Angela Wang, Asli Ozyurek, Paula Rubio-Fernandez To appear In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics. ACL oral presentation (<5% of submissions). paper Multimodal language models (MLMs) increasingly demonstrate human-like communication, yet their use of everyday perspectival words remains poorly understood. To address this gap, we compare humans and MLMs in their use of three word types, which we predict impose increasing cognitive demands: vocabulary (e.g., 'boat' or 'cup'), possessives (e.g., 'mine' vs. 'yours'), and demonstratives (e.g., 'this one' vs. 'that one'). Testing seven MLMs against human participants, we find that perspectival words are harder than vocabulary words for both groups. The gap is even larger for MLMs: while models approach human-level performance on using vocabulary, they exhibit clear deficits with possessives and even greater difficulties with demonstratives. Ablation analyses point to limitations in perspective-taking and spatial reasoning as key sources of these gaps in MLMs. Instruction-based prompting helps close the gap for possessives but still leaves demonstratives far below human performance. These results show that, unlike vocabulary, perspectival words pose a greater challenge in human communication—and this difficulty is further amplified in MLMs, revealing a crucial shortfall in their pragmatic and social-cognitive abilities. |

|
Dota Tianai Dong*, Jing Li*, Tobias Thomas*, Linda B. Smith In Proceedings of the Analytical Connectionism Schools 2023--2024, PMLR 320:126-150, 2026. paper These lecture notes present Linda Smith's comprehensive analysis of the statistics of natural experience and its consequences for how we think about learning and intelligence. The material explores how statistics shape behavior and learning, details a developmental curriculum, examines properties of natural statistics, and investigates the dynamic coupling of parents and toddlers. Through multiple perspectives and examples, Smith offers insights into how statistical patterns in our environment influence cognitive development and learning processes. This collection is particularly valuable for machine learning readers seeking to understand the statistical foundations of human cognition and their applications to artificial intelligence systems. |
| For a complete list, see my Research page → | |
|
|
For all activities, see my Community page → |
|
© Copyright 2026 Dota Dong. Last updated May 5, 2026.
|